고정 헤더 영역
상세 컨텐츠
본문
첫번째로 공부할 방법론은 공학 분야에서 개발되어 현재는 경제분석을 포함한 다양한 분야에서 활용되고 있는 칼만 필터이다. 주 교과서는 "<수학으로 풀어보는 칼만필터 알고리즘>, 박성수 지음, 위키북스"이다. (삽입된 그림의 출처도 동일한 책이다)
어떤 의미있는 경제분석을 시행하기 위해서는 해당 분석에 적합한 분석 재료가 있어야 한다. 여기서의 재료는 물론 데이터, 정보이다. 현대사회를 정보사회라고 하는만큼 예전에 비해서 분석이 용이해진 것이 아닌가 싶기도 하겠지만 혹자는 데이터와 정보의 의미를 구분할 필요가 있다고 한다.
데이터는 우리의 시작점이며 가공하지 않은 숫자로 정의된다. 우리는 이런 숫자들을 대량으로 모으고 저장하는 것이 가능한 데이터 시대에 살고 있다. 데이터가 정보가 되려면 가공과 분석 과정을 거쳐야 하며, 바로 이 부분에서 우리는 까다로운 문제에 직면한다. 데이터 양산은 가공해야 할 데이터가 훨씬 늘어났다는 의미인 동시에, 데이터끼리 모순된 신호를 발산하기 때문에 정보로 바꾸기가 훨씬 어려워졌다는 의미이다.
<내러티브&넘버스, 애스워드 다모다란, 한빛비즈>
즉, 현대사회는 데이터가 넘쳐나는 사회이며 이에 따라 분석에 적합한 정보를 취합하기는 오히려 더 까다로워졌다는 것이다. 이러한 배경에서 넘쳐나는 데이터에서 의미있는 양의 정보를 추려주는 필터링(flitering) 알고리즘의 존재는 매우 중요하다.
앞으로 여러 포스팅에 걸쳐 공부해 볼 칼만필터도 한마디로 측정하여 모은 데이터로부터 미지의 정보를 추정하는 일종의 추정 알고리즘(estimator)이다. 루돌프 칼만에 의해 1960년에 처음 소개된 이 알고리즘은 그 범용성과 확장성으로 인해 무수히 많은 과학, 공학 분야에서 활용되고 있으며 경제분석 분야에서는 로버트 호드릭과 에드워드 프레스콧에 의해 1997년 HP filter라는 형식으로 처음 소개되어 현재까지도 활용되고 있다.

이 포스팅 시리즈의 마무리 단계에서는 HP filtering 알고리즘을 직접 짜보고 실제 거시 데이터에 적용하는 것까지 해보도록 하겠다.
이번 포스팅에서는 교과서에서 소개된 기초 개념만 몇가지 짚도록 하자.
먼저 데이터에서 정보를 추정하는 방식을 3가지로 구분할 수 있다. 예측(prediction)은 현재까지의 데이터를 활용하여 미래의 특정시점의 상태를 추정하는 것이고 필터링(filtering)은 현재의 상태를 추정하는 것, 스무딩(smoothing)은 과거에서 미래의 데이터까지를 활용하여 현재를 추정하는 것이다. 칼만필터를 활용하여 3가지 방식 모두를 추정할 수 있다고는 하는데 일단은 경제분석에서 제일 많이 활용되는 예측에만 일단 집중해서 공부를 해보도록 하자.
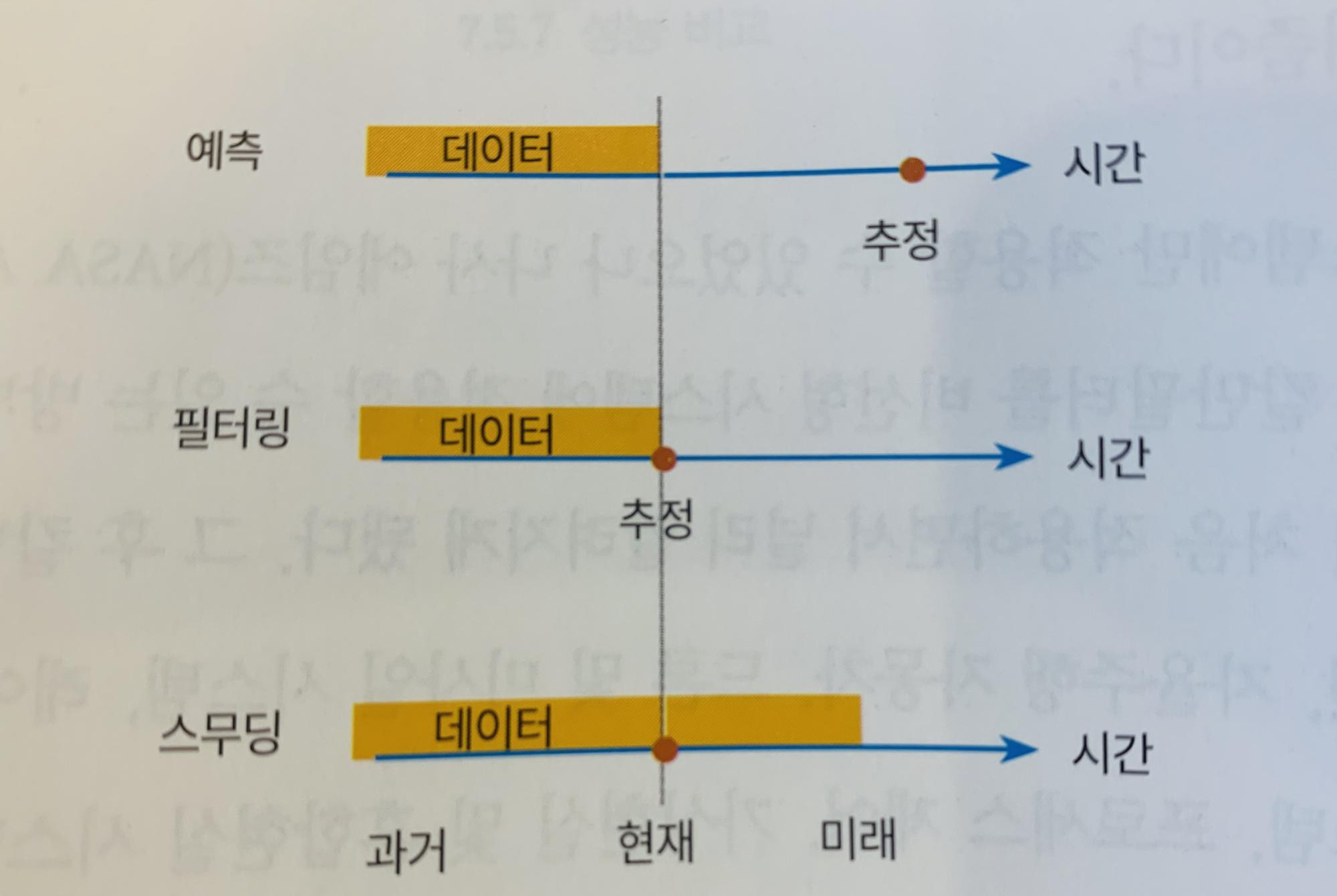
자꾸 언급되는 상태라는 것은 우리가 수학적으로 계산하기 위하여 변수화한 대상으로 예컨대 경기변동을 분석하고자 한다면 GDP, 소비, 투자 등이 상태변수가 된다. 우리는 이러한 변수 관련 데이터에 일종의 신호처리를 하여 미래 상태를 예측하고 싶은 것이다. 상태를 추정하는 시스템 모델은 아래의 그림처럼 상태변수, 외부 입력변수, 노이즈 등을 포함하는 함수로 표현된다.
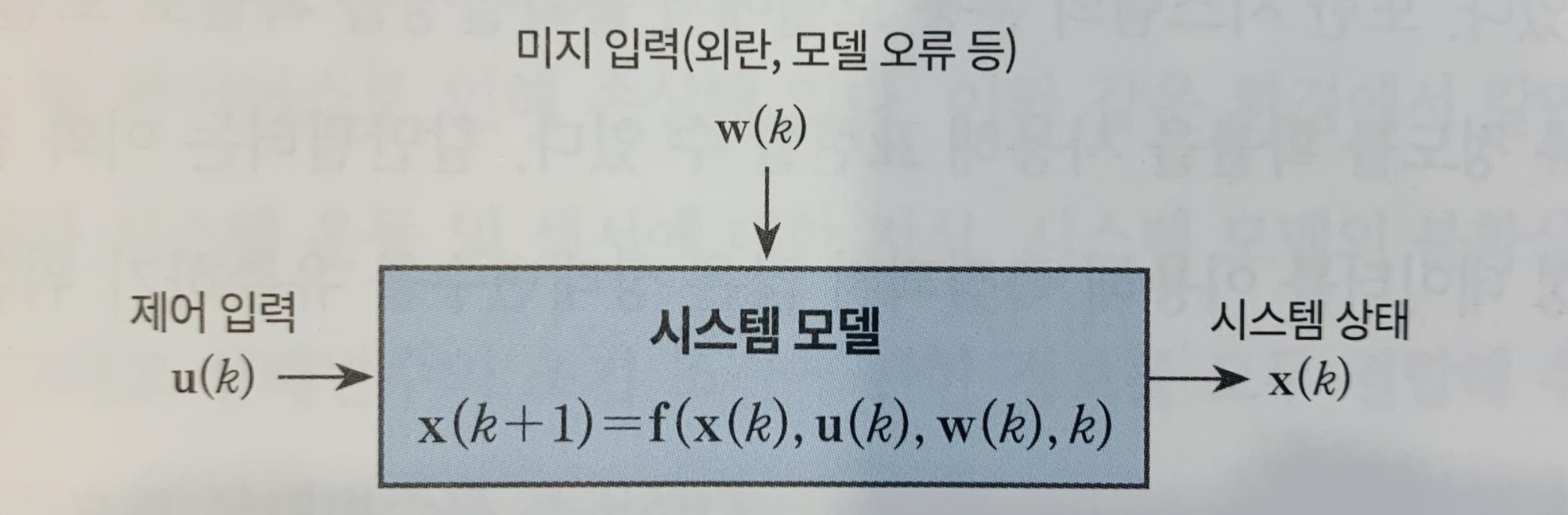
책에 언급되어 있듯이 위 모델의 핵심은 바로 함수 f(·)가 어떻게 생겼냐는 것이다. 칼만필터의 성능은 시스템 모델의 정확성에 크게 의존하기 때문이다. 경제학에서는 이러한 모델을 개발하는 이론경제학자들이 있어 오랜기간 통용되고 인정받은 모델을 활용하여 설계할 수 있을 것이다.

측정 모델은 우리가 관찰하는 값과 측정하고자 하는 값과의 괴리를 줄이는 것을 목표로 한다. 경제 분야에서는 각국의 중앙은행이나 국제기구 등에서 많은 양의 데이터를 생산하고 있는데, 이를 그 자체로 측정값으로 활용할 수도 있고 존재할 수 있는 편향이나 노이즈를 제거하는 식으로 가공해서 새로운 측정값을 만들어낼 수도 있겠다.
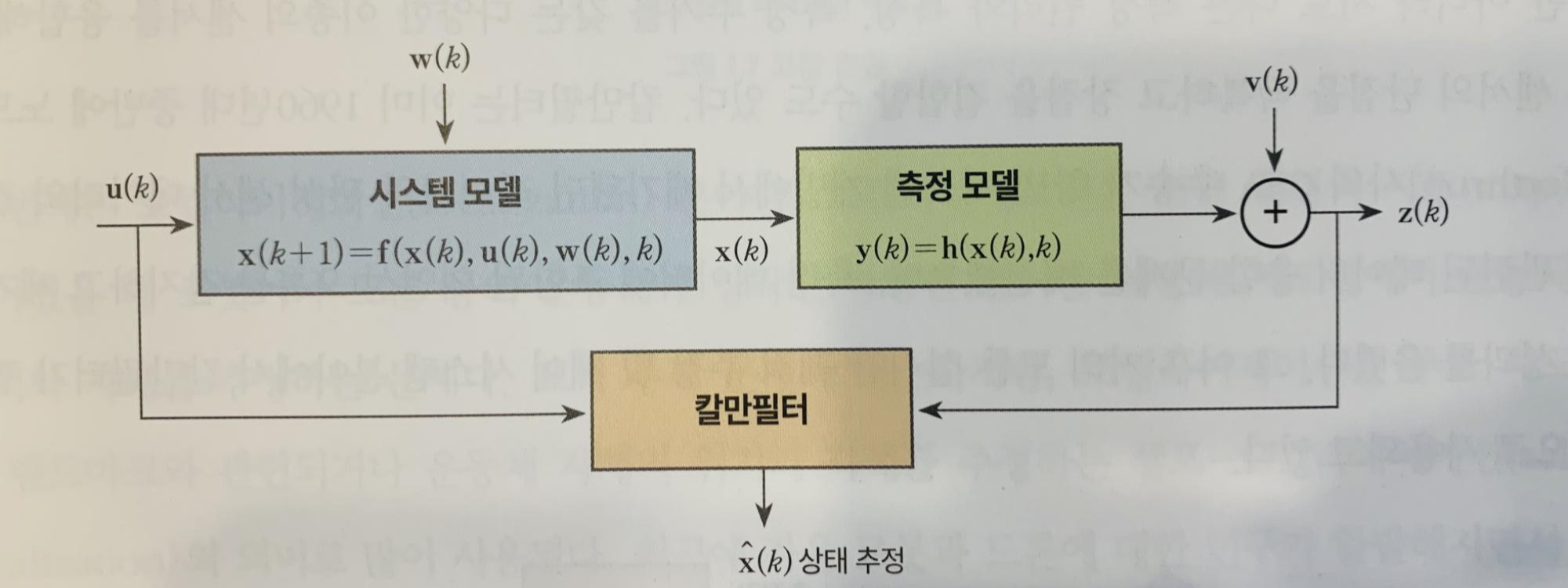
지금까지 언급한 모델을 모두 통합한 것이 바로 칼만필터의 기초적인 틀이다. 책에서 언급하고 있는 칼만필터의 광범위한 응용분야 중 하나는 시스템 식별(identification)과 고장검출 분야이다.
시스템 식별이란 시스템 모델의 구조는 알고 있으나 시스템을 구성하는 특정 파마리터(질량, 향력 계수) 등의 값을 알 수 없는 경우, 이와 같은 미지의 파라미터를 상태변수로 변환해 식별하는 것을 의미한다. 고장검출이란 고장이 발생했을 때 변화가 생기는 파라미터를 측정하거나 식별하여 시스템 고장여부를 판단하거나 칼만필터를 통해 산출한 측정 예측값과 실제로 관측되는 측정값 사이의 잔차를 이용하여 판단하는 것을 의미한다.
위에서는 공학적인 용어를 활용하고 있어서 자칫 생소해 보일 수 있는데 핵심적인 아이디어를 파악한다면 경제분석에서 정확히 대응되는 개념이 무엇인지 알 수 있다. 예컨데 시스템 모델이라는 것은 경제이론을 의미하며 식별하고자 하는 파라미터는 승수나 탄력성 등이 될 것이다. 특히 식별(identification)이 얼마나 중요하게 언급되는 부분인지 경제학을 조금이라도 공부해 본 사람이라면 잘 알 것이다. 고장검출도 예컨대 경제의 근본적인 구조를 반영하는 모수(상수로 가정하였던)에 어떤 구조적인 변화가 발생했을 때, 혹은 예측 오차가 발생했을 때 이를 모델링하는 분야라고 생각할 수 있겠다.
요약
-
칼만필터는 신호와 노이즈가 섞여있는 데이터를 의미있는 정보로 변환 해주는 필터링 알고리즘이다.
-
노이즈를 최소화하여 식별하고자 하는 시스템의 상태를 구체화하여 측정, 분석할 수 있게 해주는 기초적인 방법론으로 경제학(HP filtering)을 포함한 다양한 분야에서 활용된다.
다음시간에는 본격적인 알고리즘 공부 전 필요한 기초 수학내용을 정리해보도록 하겠다!
'내러티브& 넘버스 > 방법론' 카테고리의 다른 글
| Hard data vs. Soft data/ 경기상황 판단 및 분석에 관하여 (0) | 2020.08.13 |
|---|





댓글 영역